Sporą część naszych wystąpień w Poznaniu (Data on Campus, 26.10.2024) oraz w Warszawie (Data Science Summit, 22.11.2024) poświęciliśmy kwestii dostrajania modeli językowych na instrukcjach (ang. instruction fine tuning) oraz wychowania ich na preferencjach (ang. alignment). Opowiadaliśmy o związanych z tym wyzwaniach metodologicznych, omawiając możliwe ścieżki pozyskiwania danych uczących – od danych organicznych w języku polskim, przez gotowe zbiory tłumaczone z innych języków, aż po dane syntetyczne. Każda z tych ścieżek ma swoje zalety i wady, które staraliśmy się rzetelnie przeanalizować i przedstawić.
Podkreślaliśmy nieocenioną wartość własnych, oryginalnych zbiorów instrukcji oraz preferencji tworzonych mozolnie przez anotatorów i anotatorki według precyzyjnych wytycznych. Wyraźnie artykułowaliśmy też szereg ograniczeń zbiorów syntetycznych, przedstawiając destylację wiedzy i kompetencji z istniejących modeli jako wygodną, lecz obarczoną licznymi ryzykami drogę na skróty. Już wtedy podaliśmy przykład odpowiedzi modeli z rodziny Qwen na pytania o wydarzenia z Placu Tiananmen, które jasno pokazywały problematyczne aspekty destylacji.
Te pozornie akademickie rozważania warto przypomnieć w kontekście dyskusji o udostępnionych niedawno modelach DeepSeek. Choć wiele doniesień na ich temat opiera się na domysłach i anegdotycznych przykładach, wyraźnie zarysowują się dwa wątki. Po pierwsze podkreśla się orientację światopoglądową wpojoną tym modelom i tu podawane są przykłady pytań, które w zeszłym roku testowaliśmy na modelach Qwen. Po drugie pojawiają się informacje o zastosowaniu przez twórców i twórczynie modeli DeepSeek technik masowej destylacji wiedzy i kompetencji np. z modeli OpenAI.
Zidentyfikowane przez nas ryzyka destylacji, czyli generowania syntetycznych danych uczących z istniejących modeli, podsumowuje poniższy slajd.
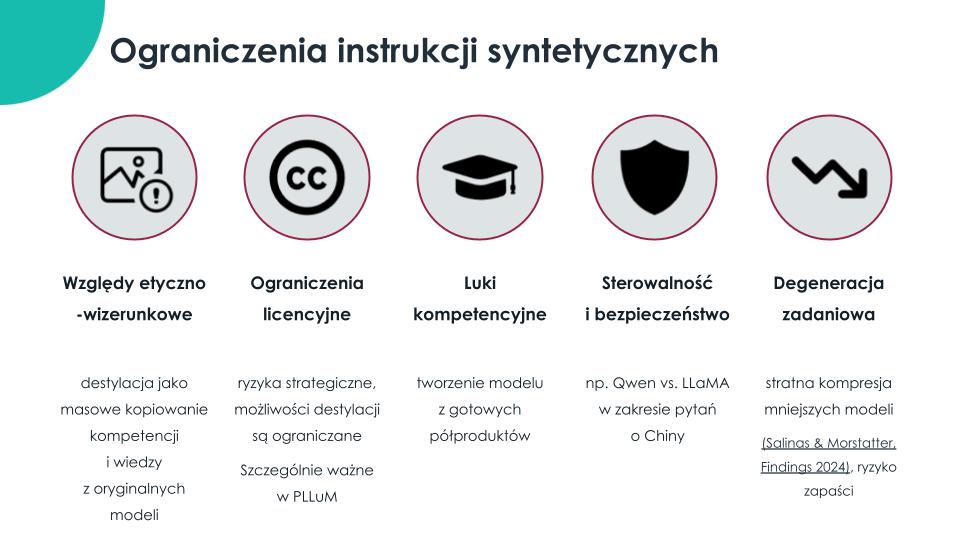 Rys. 1. Slajd z prezentacji Metodologia i proces tworzenia dużego polskiego modelu językowego (Data on Campus, 26.10.2024)
Rys. 1. Slajd z prezentacji Metodologia i proces tworzenia dużego polskiego modelu językowego (Data on Campus, 26.10.2024)- Względy etyczno-wizerunkowe: masowe kopiowanie wiedzy i kompetencji z istniejących modeli trudno porównywać pod względem naukowym, organizacyjnym czy finansowym z tworzeniem modeli od podstaw. Brak inwestycji w oryginalne, wysokiej jakości dane znacząco obniża rzeczywistą wartość projektu. Korzystanie z destylacji sprawia także, że nowy model staje się zależny od jakości i standardów etycznych przyjętych przez twórców i twórczynie modelu źródłowego. Procesy uczenia oraz źródła danych takich modeli często nie są w pełni transparentne, co utrudnia rzetelną ocenę ich jakości i zgodności z dobrymi praktykami. Co więcej, modele destylowane mogą nie spełniać lokalnych wymogów prawnych, np. dotyczących ochrony danych osobowych.
- Ograniczenia licencyjne: większość modeli, zarówno zamkniętych, jak i otwartych, objęta jest licencjami, które wykluczają nieograniczone generowanie danych na potrzeby tworzenia modeli pochodnych. Zakaz zastosowania oferowanych rozwiązań do budowania konkurencyjnych modeli językowych został wyraźnie ujęty m.in. w warunkach korzystania z modeli OpenAI (“You may not: [...] Use Output to develop models that compete with OpenAI”) i Anthropic (“You may not access or use, or help another person to access or use, our Services [...] to develop any products or services that compete with our Services, including to develop or train any artificial intelligence or machine learning algorithms or models”).
- Luki kompetencyjne: przejście przez etap tworzenia własnych, oryginalnych zbiorów danych uczących, takich jak korpusy instrukcji i preferencji, rozwija kompetencje z zakresu dostrajania i wychowywania modeli. Pomijanie tego etapu może prowadzić do technologicznego uzależnienia od zewnętrznych modeli. Kompetencje zdobyte podczas wytwarzania danych zapewniają istotne przewagi w budowie kolejnych modeli oraz samowystarczalność w kluczowych obszarach rozwoju AI.
- Sterowalność i bezpieczeństwo: masowa destylacja z wielkich modeli może oznaczać przenoszenie zaszytych w nich błędów i obciążeń (ang. biases) oraz preferencji światopoglądowych. Takie ideologiczne skrzywienie modelu może przejawiać się w bardzo subtelny sposób. Na przykład model X może wbrew oczekiwaniom swoich docelowych użytkowników rzadziej klasyfikować jako obraźliwe treści zgodne ideologią wpojoną na etapie wychowywania na preferencjach.
- Degeneracja zadaniowa: występujący w procesie destylacji instrukcji transfer wiedzy i umiejętności z modeli wielojęzycznych na modele spolszczone często kończy się negatywnym transferem językowym.
 Rys. 2. Przykład negatywnego transferu językowego
Rys. 2. Przykład negatywnego transferu językowego W kontekście degeneracji zadaniowej warto ponownie powołać się na przykład modeli DeepSeek. Ponieważ flagowy model ma prawie 700 mld wag i nawet jego testowe uruchomienie wymaga 8 kart Nvidia H200 (koszt jednej to około 200 tys. zł), popularne stają się modele stanowiące jego pochodne. Zresztą sama firma DeepSeek dokonała destylacji swojego flagowego modelu do mniejszych rozmiarów na bazie modeli Qwen i Llama. Największy z modeli pochodnych oparty jest na Llamie 70B. W rodzinie modeli PLLuM znajdują się m.in. modele oparte właśnie na Llamie 70B. Dlatego naturalnym krokiem było porównanie obu podejść bazujących na tym samym modelu źródłowym, ale różnie realizowanych. W projekcie PLLuM wyszliśmy od bazowej Llamy, trenowaliśmy ją drogą językowej adaptacji na polskojęzycznym korpusie, a następnie stroiliśmy i wychowywaliśmy na autorskich instrukcjach i preferencjach. DeepSeek wystartował od instrukcyjnej Llamy i dokonał strojenia na instrukcjach masowo pozyskanych z DeepSeek-R1. Wstępne analizy wskazują, że były to głównie dane w językach angielskim i chińskim. W efekcie działanie modelu w językach innych niż wymienione uległo istotnemu pogorszeniu. Na przykład w niezależnym benchmarku testującym znajomość kultury, historii i języka polskiego model DeepSeek-R1-Distill-Llama-70B uzyskał wynik ok. 44, podczas gdy instrukcyjna Llama 70B osiągnęła wynik o 5 punktów wyższy. Również analizy modeli w zastosowaniach typowych dla generatorów w systemach RAG-owych potwierdziły degenerację zadaniową modelu opartego na danych destylowanych. To wszystko pokazuje, że zalewanie modeli syntetycznymi instrukcjami w bardzo ograniczonej puli języków może prowadzić do kontraadaptacji, czyli pogarszania się właściwości językowych modelu w zastosowaniach lokalnych np. w kontekście języków rzadkich, jakim dla twórców i twórczyń modeli chińskich i anglosaskich jest język polski.
Przykład z logu: Model DeepSeek-R1-Distill-Llama-70B odpowiada na pytanie, uwzględniając podany kontekst dokumentów. Na wejściu otrzymał zarówno pytanie, jak i kontekst, który zawierał odpowiednie informacje.
Pobudzenie: Do czego służył prodiż?
Odpowiedź: Prodiż to popularny polski program do wydajności odtwarzacza multimedialnego, który służy do odtwarzania plików audio i wideo. Był szczególnie popularny w latach 90. i na początku XXI wieku. Główne funkcje programu obejmują:
1. Odtwarzanie plików multimedialnych: Prodiż obsługuje wiele formatów audio i wideo, takich jak AVI, MPEG, MP3, WAV itp.
2. Korektor audio: Użytkownik może dostosować brzmienie dźwięku poprzez regulację bassu, trebli, echo itp.
3. Obsługa pluginów: Program pozwala na instalowanie dodatkowych wtyczek, które rozszerzają jego funkcjonalność, np. o nowe kodeki lub efekty dźwiękowe.
4. Proste interfejs: Intuicyjny interfejs ułatwia korzystanie z programu nawet mniej doświadczonym użytkownikom.
Prodiż był często używany do odtwarzania muzyki i filmów na komputerach z systemem Windows, zwłaszcza w okresie, gdy inne odtwarzacze multimedialne nie oferowały takiej samej wydajności i elastyczności.
W modelach PLLuM wykorzystujemy autorskie zbiory organicznych instrukcji oraz preferencji. Z technik destylacji staramy się korzystać w ograniczonym, dobrze kontrolowanym zakresie. Już wkrótce udostępnimy reprezentatywne podzbiory naszych zasobów oraz dokumentację pełnych korpusów.