
1. Dane
Zgromadziliśmy obszerne zbiory wysokiej jakości danych tekstowych, w tym utwory niedostępne publicznie, pochodzące bezpośrednio od wydawców i pozyskane na podstawie umów licencyjnych (listę instytucji, które przekazały nam dane, znaleźć można w zakładce partnerzy). Są to przede wszystkim dane w języku polskim (po czyszczeniu i deduplikacji ok. 150 mld tokenów, w tym ponad 28 mld tokenów, które – zgodnie z ustawą o prawie autorskim i prawach pokrewnych oraz regulacjami UE – mogą posłużyć do budowy w pełni otwartego modelu, w tym również do zastosowań komercyjnych*), ale także w innych językach słowiańskich i bałtyckich oraz w języku angielskim, co służy lepszemu uogólnieniu modeli.
Opracowaliśmy największy polskojęzyczny zbiór organicznych instrukcji (ok. 40 tys., w tym prawie 3,5 tys. wieloturowych), a więc pobudzeń (promptów) oraz oczekiwanych odpowiedzi modeli przygotowywanych ręcznie przez zespół anotatorów i anotatorek według stale aktualizowanych wytycznych. Takie podejście pozwala nam zrozumieć różne aspekty procesu dostrajania (SFT), które łatwo przeoczyć w innych podejściach. Zbiór instrukcji organicznych uzupełniliśmy instrukcjami konwertowanymi z wysokiej jakości polskojęzycznych zasobów korpusowych i leksykalnych oraz instrukcjami syntetycznymi, tworzonymi z użyciem dużych modeli językowych.
Utworzyliśmy pierwszy polskojęzyczny korpus preferencji, czyli pobudzeń (promptów) i różnych odpowiedzi modeli ręcznie ocenianych przez zróżnicowaną demograficznie grupę anotatorów i anotatorek. Poprzez preferencje chcieliśmy nauczyć model tworzenia odpowiedzi nie tylko poprawnych – zarówno merytorycznie, jak i językowo – lecz także możliwie wyważonych i bezpiecznych. Nacisk położyliśmy więc na zagadnienia o potencjalnie kontrowersyjnym charakterze i testujące odporność modeli na ataki. Prace anotacyjne obejmowały tworzenie rankingu odpowiedzi różnych modeli (ponad 18 tys. pobudzeń, co daje od prawie 37 tys. do ponad 110 tys. par odpowiedzi preferowanych i odrzucanych), ocenę odpowiedzi jednego modelu w odniesieniu do szczegółowych kryteriów, takich jak pomocność czy bezstronność (ok. 8 tys.), oraz wybór preferowanej odpowiedzi w bezpośredniej, wieloturowej interakcji z modelem (ponad 10 tys.).
Opracowaliśmy wreszcie autorskie zbiory ewaluacyjne umożliwiające ocenę działania modeli w różnych zastosowaniach. W zadaniach związanych z administracją publiczną modele PLLuM uzyskały najlepsze wyniki spośród wszystkich testowanych przez nas modeli. Co więcej, nasze modele osiągają najwyższe rezultaty w zadaniach przygotowanych do ewaluacji zastosowań w języku polskim potraktowanych zbiorczo.
2. Modele
Utworzyliśmy nie jeden, lecz całą rodzinę modeli językowych o wielkości od 7 do 70 mld parametrów, dostosowanych do różnorodnych zadań w języku polskim. Budowaliśmy modele od podstaw, a także adaptowaliśmy i rozwijaliśmy otwarte modele fundamentalne na bazie wysokiej jakości danych polskojęzycznych, zapewniających dokładność i kontekstową spójność w rozumieniu języka polskiego. Opracowaliśmy największy polski LLM i jako pierwsi podjęliśmy się adaptacji językowej (tj. kontynuacji pretreningu na danych polskojęzycznych) modeli Mixture of Experts (MoE) o wielkości 8x7 mld parametrów czy modelu Llama 70 mld parametrów na tak dużą skalę. Nasze podejście obejmuje nie tylko pre-trening, lecz także dostrajanie na podstawie instrukcji (ang. instruction fine tuning), wychowanie (ang. alignment), czyli dostosowywanie modeli do preferencji użytkowników i użytkowniczek, oraz dodatkowe zabezpieczenie w postaci filtracji i korekty wyjścia z modelu z wykorzystaniem autorskich klasyfikatorów.
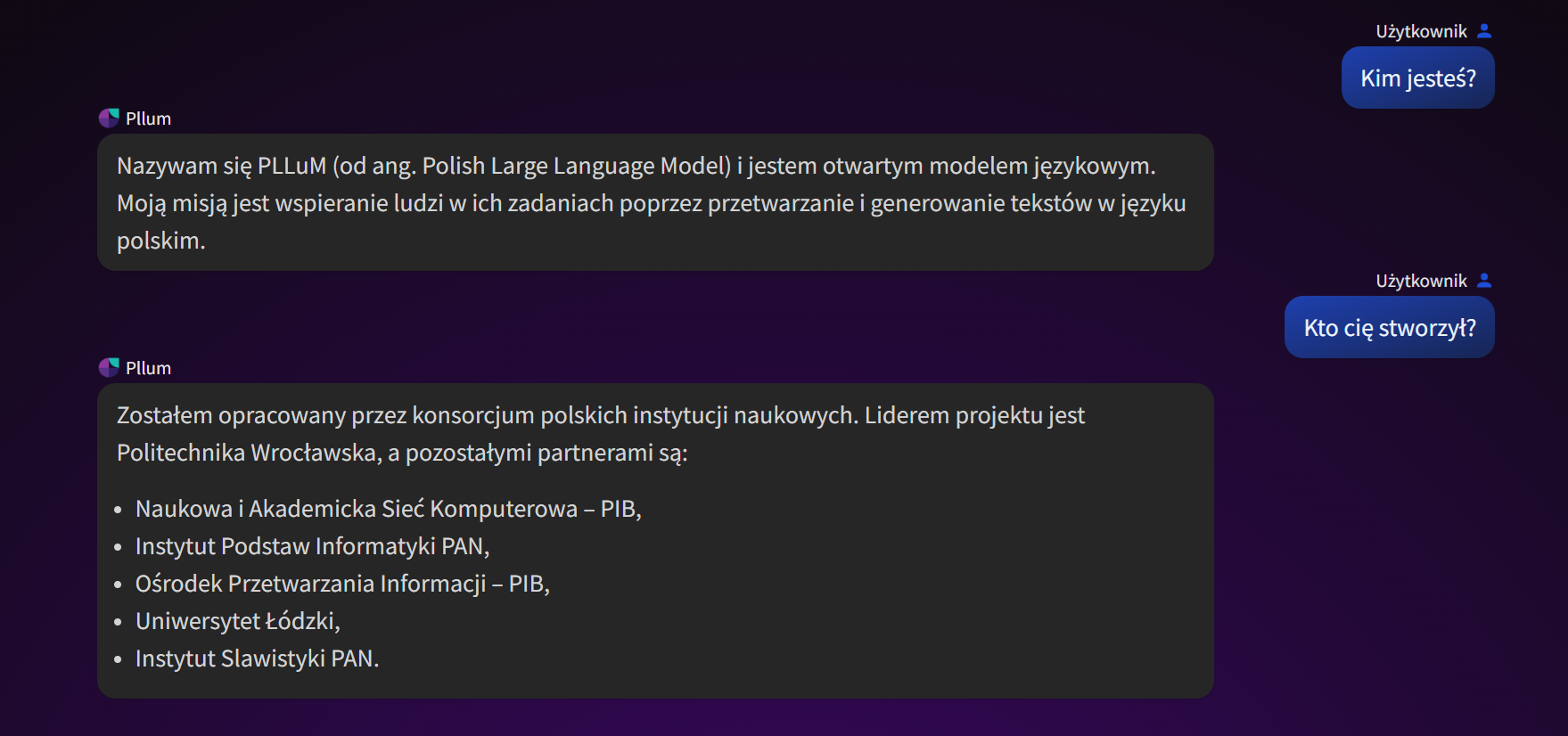 Rys. 1. PLLuM-12B w działaniu
Rys. 1. PLLuM-12B w działaniu3. Inteligentny asystent
Obok modeli ogólnego zastosowania utworzyliśmy generatory, czyli wyspecjalizowane modele RAG-owe (ang. Retrieval Augmented Generation), które na podstawie zapytania w języku naturalnym oraz wyszukanych kontekstów (tj. dokumentów najbardziej pasujących do zapytania) generują końcową odpowiedź. Zbudowaliśmy najmniejszy (8 mld parametrów) i obecnie najlepszy w Polsce generator do RAG-a, co potwierdziły wyniki ewaluacji w schemacie RAG-if-eval.
W ramach prac nad prototypem inteligentnego asystenta dla polskiej administracji publicznej opracowaliśmy skalowany serwis do udostępniania usług asystentów (tj. backend asystenta). Na tej bazie stworzyliśmy narzędzie Shparag do sprawnego „składania” i kontrolowanego testowania RAG-ów o różnych konfiguracjach.
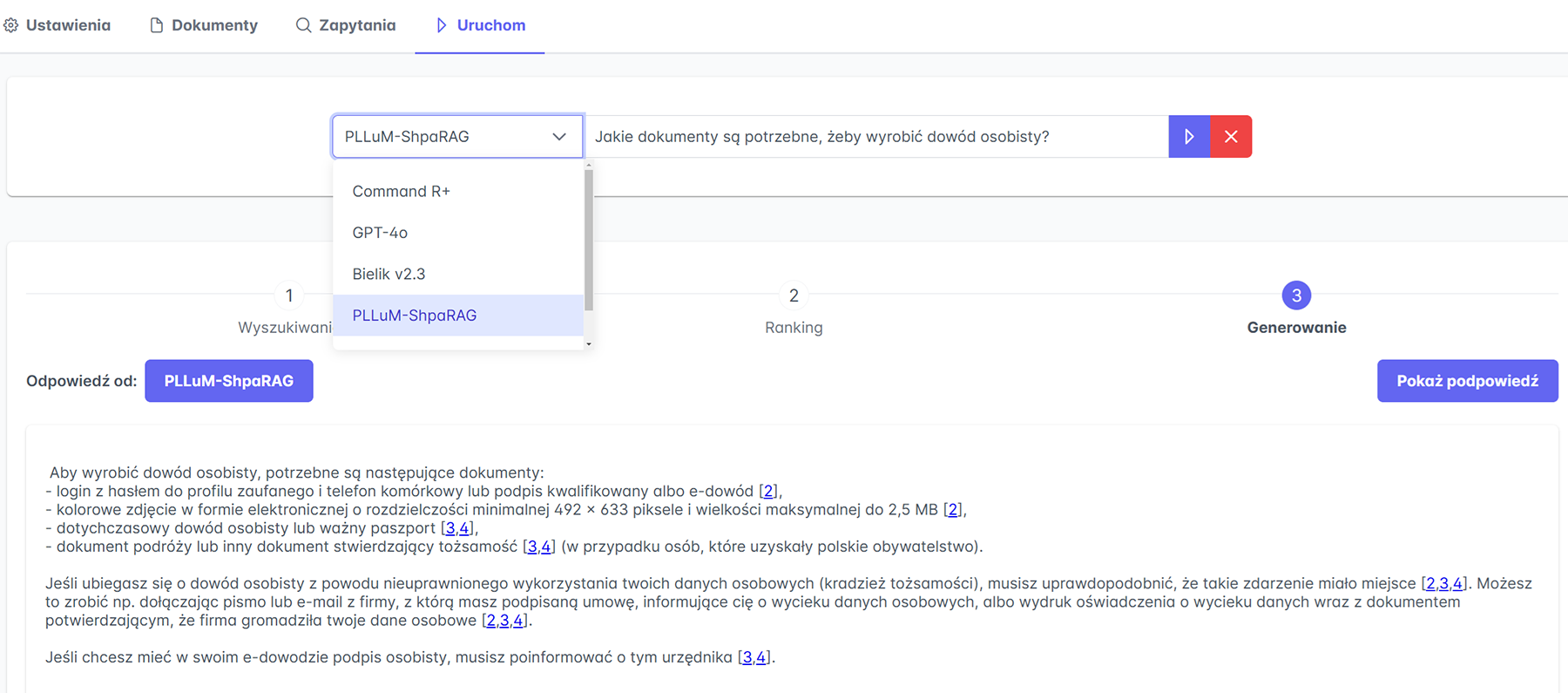 Rys. 2. Shparag w działaniu
Rys. 2. Shparag w działaniu W prototypowym rozwiązaniu bazę wiedzy stanowią dokumenty pobrane z publicznych domen gov.pl. Zebraliśmy także kilkadziesiąt tysięcy dokumentów o tematyce urzędowo-prawnej z innych źródeł, które są używane do trenowania i ewaluacji modeli.
 Rys. 3. Projekt interfejsu inteligentnego asystenta
Rys. 3. Projekt interfejsu inteligentnego asystenta Kiedy i w jaki sposób udostępnimy modele?
Modele z rodziny PLLuM i prototyp inteligentnego asystenta są od początku listopada 2024 roku testowane przez Ministerstwo Cyfryzacji. W grudniu – zgodnie z postanowieniami umowy dotacyjnej – dwa w pełni otwarte modele z rodziny PLLuM, a konkretnie Llama-PLLuM-8B oraz PLLuM-12B, zostały przekazane Ministerstwu. Zostaną one upublicznione możliwie szybko, zaraz po wystawieniu przez MC, które jest właścicielem wytworzonych w projekcie modeli, odpowiednich licencji. Inne modele, w szczególności modele naukowe uczone na pełnym zbiorze danych (150 mld tokenów) oraz modele otwarte również dla zastosowań komercyjnych o rozmiarach 8x7B i 70B, zostaną opublikowane przez Konsorcjum – po podpisaniu z MC porozumienia określającego licencje – w pierwszym kwartale 2025 roku. Mamy nadzieję, że nastąpi to jeszcze w styczniu. W pierwszym kwartale 2025 roku ukaże się również biała księga (ang. white paper), w której opisane zostaną wszystkie etapy prac nad modelami PLLuM.
Co dalej?
Nie powiedzieliśmy oczywiście ostatniego słowa. Kompetencje, zasoby i rozwiązania, które wypracowaliśmy w projekcie PLLuM, pozwolą nam na przeniesienie działań na wyższy poziom i przejście z fazy stricte badawczej w fazę wdrożeniową. Więcej szczegółów podamy już wkrótce.
- Agnieszka Karlińska
- Jan Kocoń
- Maciej Piasecki
- Piotr Pęzik
- Marek Kozłowski
- Maciej Ogrodniczuk
- Roman Roszko
*W projekcie PLLuM proces pozyskiwania danych poprzedzony został szczegółową analizą uwarunkowań prawnych, w szczególności analizą (i) ustawy z dn. 4 lipca 1994 r. o prawie autorskim i prawach pokrewnych, (ii) przepisów prawa UE właściwych dla ochrony praw autorskich, w tym AI Act, oraz (iii) ustawy z dnia 27 lipca 2001 r. o ochronie baz danych. W związku z nowelizacją ustawy o prawie autorskim z 20.09.2024 do treningu modelu w pełni otwartego (tj. do zastosowań komercyjnych i niekomercyjnych) dozwolone jest obecnie wykorzystanie danych internetowych, pod warunkiem że wydawca nie zastrzegł, że nie wyraża na to zgody. W przypadku modeli tworzonych dla celów badawczych przez instytucje wymienione w ustawie, w tym uczelnie i instytuty badawcze, dozwolone jest korzystanie z danych internetowych niezależnie od ewentualnych zastrzeżeń. Dlatego przyjęliśmy dwie ścieżki pracy nad modelami i zarazem dwie ścieżki ich udostępniania: naukową (modele publikowane na licencji niepozwalającej na zastosowania komercyjne) oraz w pełni otwartą (modele publikowane na licencji pozwalającej na zastosowania komercyjne). Korpus do uczenia modeli otwartych (tzw. korpus biały) jest mniejszy niż korpus do uczenia modeli naukowych (150 mld tokenów vs 28 mld tokenów), ale w projekcie zadbaliśmy o to, żeby był on jak najwyższej jakości i możliwie zrównoważony. Dane włączone do tego korpusu pochodzą z trzech głównych źródeł: (i) zasobów konsorcjantów, (ii) bezpośrednio od wydawców (na podstawie umów licencyjnych) oraz (iii) zbiorów otwartych danych. Dodatkowo do korpusu włączone zostały wyselekcjonowane dane internetowe, które spełniają kryteria wymienione w ustawie, tj. zostały zweryfikowane pod kątem zastrzeżeń dotyczących pól ich eksploatacji. Poza weryfikacją zastrzeżeń zastosowaliśmy złożone procedury deduplikacji i czyszczenia danych.